How do you preprocess a dataset in Matlab?
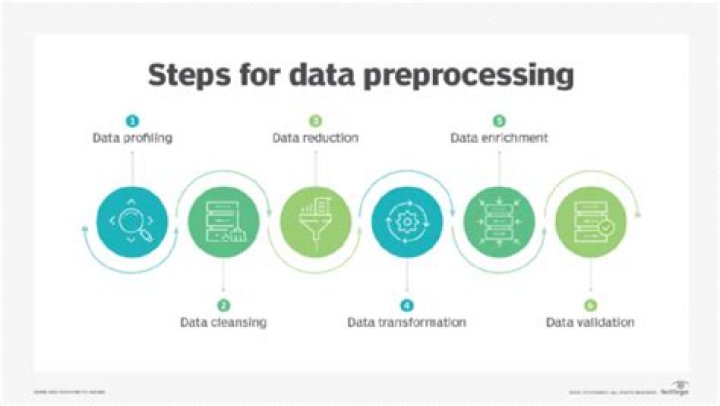
Ways to Preprocess Data
- Remove Offset — Remove mean values, a constant value, or an initial value from the data.
- Scale Data — Scale data by a constant value, signal maximum value, or signal initial value.
- Extract Data — Select a subset of the data to use in the .
What is the correct way to preprocess the data?
Steps in Data Preprocessing in Machine Learning
- Acquire the dataset. Acquiring the dataset is the first step in data preprocessing in machine learning.
- Import all the crucial libraries.
- Import the dataset.
- Identifying and handling the missing values.
- Encoding the categorical data.
- Splitting the dataset.
- Feature scaling.
How do you normalize a dataset in Matlab?
Description. N = normalize( A ) returns the vectorwise z-score of the data in A with center 0 and standard deviation 1. If A is a vector, then normalize operates on the entire vector. If A is a matrix, table, or timetable, then normalize operates on each column of data separately.
What is pre processing in Matlab?
Data cleaning, smoothing, grouping. Data can require preprocessing techniques to ensure accurate, efficient, or meaningful analysis. Data cleaning refers to methods for finding, removing, and replacing bad or missing data.
Why do we preprocess data?
It is a data mining technique that transforms raw data into an understandable format. Raw data(real world data) is always incomplete and that data cannot be sent through a model. That would cause certain errors. That is why we need to preprocess data before sending through a model.
How do you normalize data between two values?
To normalize the values in a dataset to be between 0 and 100, you can use the following formula:
- zi = (xi – min(x)) / (max(x) – min(x)) * 100.
- zi = (xi – min(x)) / (max(x) – min(x)) * Q.
- Min-Max Normalization.
- Mean Normalization.
Why do you normalize data?
The goal of normalization is to change the values of numeric columns in the dataset to use a common scale, without distorting differences in the ranges of values or losing information. Normalization is also required for some algorithms to model the data correctly.
What is data preprocessing in data science?
Data preprocessing is the process of transforming raw data into an understandable format. The quality of the data should be checked before applying machine learning or data mining algorithms. …
What is data preprocessing in research?
Preprocessing Data Data cleaning, smoothing, grouping Data can require preprocessing techniques to ensure accurate, efficient, or meaningful analysis. Data cleaning refers to methods for finding, removing, and replacing bad or missing data.
How do I preprocess my I/O data?
After you import I/O data, on the Plant Identification tab, use the Preprocess menu to select a preprocessing operation. Remove Offset — Remove mean values, a constant value, or an initial value from the data.
How do I perform data preprocessing with predictive maintenance?
You can perform data preprocessing on arrays or tables of measured or simulated data that you manage with Predictive Maintenance Toolbox™ ensemble datastores. For an overview of some common types of data preprocessing, see Data Preprocessing for Condition Monitoring and Predictive Maintenance.
How do I preprocess plant data before estimation?
In PID Tuner, you can preprocess plant data before you use it for estimation. After you import I/O data, on the Plant Identification tab, use the Preprocess menu to select a preprocessing operation. Remove Offset — Remove mean values, a constant value, or an initial value from the data.